Une base de données (en anglais database), permet de stocker et de retrouver l'intégralité de données brutes ou d'informations en rapport avec un thème ou une activité ; celles-ci peuvent être de natures différentes et plus ou moins reliées entre elles. En effet, leurs données peuvent y être très structurées (base de données relationnelles par exemple), ou bien hébergées sous la forme de données brutes déstructurées (base de données NoSQL Redis par exemple) qui, dans ce cas, seront ensuite parcourues de manière organisée au moment de la lecture via des moteurs spécifiques (comme Elasticsearch). Une base de données peut être localisée dans un même lieu et sur un même support informatisé, ou réparties sur plusieurs machines à plusieurs endroits (base de données NoSQL par exemple).
La base de données est au centre des dispositifs informatiques de collecte, mise en forme, stockage et utilisation d'informations. Le dispositif comporte un système de gestion de base de données (abréviation : SGBD) : un logiciel moteur qui manipule la base de données et dirige l'accès à son contenu. De tels dispositifs comportent également des logiciels applicatifs, et un ensemble de règles relatives à l'accès et l'utilisation des informations.
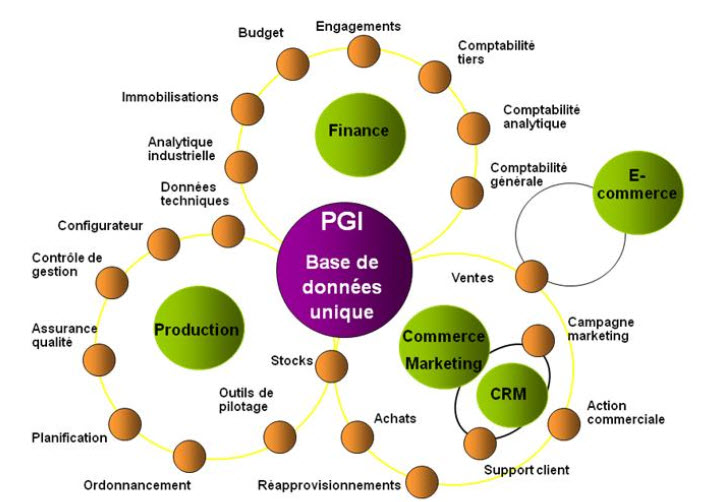
La manipulation de données est une des utilisations les plus courantes des ordinateurs. Les bases de données sont par exemple utilisées dans les secteurs de la finance, des assurances, des écoles, de l'épidémiologie, de l'administration publique (notamment les statistiques) et des médias.
En informatique, une base de données relationnelle est une base de données où l'information est organisée dans des tableaux à deux dimensions appelés des relations ou tables1, selon le modèle introduit par Edgar F. Codd en 1970. Selon ce modèle relationnel, une base de données consiste en une ou plusieurs relations. Les lignes de ces relations sont appelées des nuplets ou enregistrements. Les colonnes sont appelées des attributs.
Les logiciels qui permettent de créer, utiliser et maintenir des bases de données relationnelles sont des systèmes de gestion de base de données relationnels (SGBDR).
Pratiquement tous les systèmes relationnels utilisent le langage SQL pour interroger les bases de données. Ce langage permet de demander des opérations d'algèbre relationnelle telles que l'intersection, la sélection et la jointure
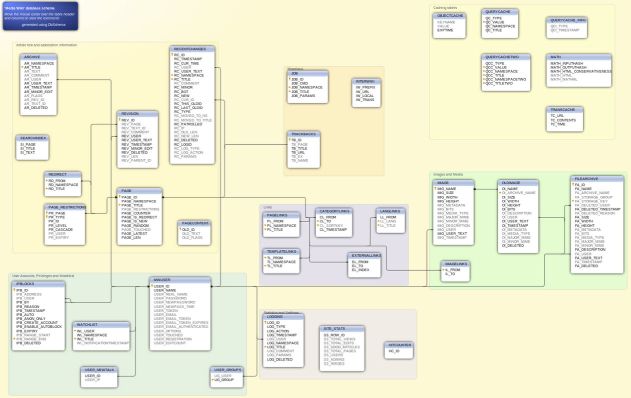
Le schéma ou modèle de données, est la description de l'organisation des données. Il se trouve à l'intérieur de la base de données, et renseigne sur les caractéristiques de chaque type de donnée et les relations entre les différentes données qui se trouvent dans la base de données. Il existe plusieurs types de modèles de données (relationnel, entité-association, objet, hiérarchique et réseau).
Le modèle de données logique — ou conceptuel — est la description des données telles qu'elles sont dans la pratique, tandis que le modèle de données physique est un modèle dérivé du modèle logique qui décrit comment les données seront techniquement stockées dans la base de données5.
Une entité est un sujet, une notion en rapport avec le domaine d'activité pour lequel la base de données est utilisée, et concernant lequel des données sont enregistrées (exemple : des personnes, des produits, des commandes, des réservations…).
Un attribut est une caractéristique d'une entité susceptible d'être enregistrée dans la base de données. Par exemple, une personne (entité), son nom et son adresse (des attributs). Les attributs sont également appelés des champs ou des colonnes4. Dans le schéma les entités sont décrites comme un lot d'attributs en rapport avec un sujet.
Un enregistrement est une donnée composite qui comporte plusieurs champs dans chacun desquels est enregistrée une donnée. Cette notion a été introduite par le stockage dans des fichiers dans les années 1960.
Les associations désignent les liens qui existent entre différentes entités, par exemple, entre un vendeur, un client et un magasin.
La cardinalité d'une association — d'un lien entre deux entités A et B — est le nombre de A pour lesquelles il existe un B et inversement. Celle-ci peut être un-à-un, un-à-plusieurs ou plusieurs-à-plusieurs. Par exemple, un compte bancaire appartient à un seul client, et un client peut avoir plusieurs comptes bancaires (cardinalité un-à-plusieurs).
C'est le type de modèle de données le plus couramment utilisé pour la réalisation d'une base de données. Selon ce type de modèle, la base de données est composée d'un ensemble de tables (les relations) dans lesquelles sont placées les données ainsi que les liens. Chaque ligne d'une table est un enregistrement. Ces modèles sont simples à mettre en œuvre, fondés sur les mathématiques (la théorie des ensembles), ils sont très populaires et fortement normalisés.
Base de données organisée selon un modèle de données de type relationnel, à l'aide d'un SGBD permettant ce type de modèle.
Ce type de modèle est le plus couramment utilisé pour la conception de modèles de données logiques6. Selon ce type de modèle, une base de données est un lot d'entités et d'associations. Une entité est un sujet concret, un objet, une idée, pour laquelle il existe des informations. Un attribut est un renseignement concernant ce sujet — exemple le nom d'une personne. À chaque attribut correspond un domaine : un ensemble de valeurs possibles. Une association désigne un lien entre deux entités — par exemple, un élève et une école.
Ce type de modèle est fondé sur la notion d'objet de la programmation orientée objet. Selon ce type de modèle, une base de données est un lot d´objets de différentes classes. Chaque objet possède des propriétés — des caractéristiques propres, et des méthodes qui sont des opérations en rapport avec l'objet. Une classe est une catégorie d'objets et reflète typiquement un sujet concret.
Ce type de modèle de données a été créé dans les années 1960 ; c'est le plus ancien modèle de données. Selon ce type de modèle, les informations sont groupées dans des enregistrements, chaque enregistrement comporte des champs. Les enregistrements sont reliés entre eux de manière hiérarchique : à chaque enregistrement correspond un enregistrement parent.
Ce type de modèle de données est semblable au modèle hiérarchique. Les informations sont groupées dans des enregistrements, chaque enregistrement possède des champs. Les enregistrements sont reliés entre eux par des pointeurs. Contrairement aux modèles hiérarchiques, l'organisation des liens n'est pas obligatoirement hiérarchique, ce qui rend ces modèles plus polyvalents.
Dans les modèles de données relationnels, un attribut peut avoir une valeur nulle, indiquant que la donnée est absente, non disponible ou inapplicable.
Dans les modèles de données relationnels, la clé primaire est un attribut dont le contenu est différent pour chaque enregistrement de la table, ce qui permet de retrouver un et un seul enregistrement
Dans les modèles de données relationnels, une clé étrangère est un attribut qui contient une référence à une donnée connexe - dans les faits la valeur de la clé primaire de la donnée connexe.
Dans les modèles de données relationnels, il y a situation d´intégrité référentielle lorsque toutes les données référencées par les clés étrangères sont présentes dans la base de données
En informatique et en bases de données, NoSQL désigne une famille de systèmes de gestion de base de données (SGBD) qui s'écarte du paradigme classique des bases relationnelles. L'explicitation du terme la plus populaire de l'acronyme est Not only SQL (« pas seulement SQL » en anglais) même si cette interprétation peut être discutée.
La définition exacte de la famille des SGBD NoSQL reste sujette à débat. Le terme se rattache autant à des caractéristiques techniques qu'à une génération historique de SGBD qui a émergé autour des années 20102. D'après Pramod J. Sadalage et Martin Fowler, la raison principale de l'émergence et de l'adoption des SGBD NoSQL serait le développement des centres de données et la nécessité de posséder un paradigme de bases de données adapté à ce modèled'infrastructure matérielle.
L'architecture machine en clusters induit une structure logicielle distribuée fonctionnant avec des agrégats répartis sur différents serveurs permettant des accès et modifications concurrentes mais imposant également de remettre en cause de nombreux fondements de l'architecture SGBD relationnelle traditionnelle, notamment les propriétés ACID.
En informatique, les propriétés ACID (atomicité, cohérence, isolation et durabilité) sont un ensemble de propriétés qui garantissent qu'une transaction informatique est exécutée de façon fiable.
Les SGBD relationnels créés dans les années 1970 se sont progressivement imposés jusqu'à devenir le paradigme de bases de données très largement dominant au début des années 1990. Plusieurs autres modèles de bases de données ont émergé, tels les SGBD orientés objet, SGBD hiérarchiques, SGBD relationnel-objet mais leur utilisation est restée très limitée. C'est dans le courant des années 2000 avec le développement de grandes entreprises internet (Google, Amazon, eBay…) brassant des quantités énormes de données et le développement de l'informatique en grappes que la domination sans partage du modèle relationnel a été remise en question car souffrant de limites rédhibitoires pour ces nouvelles pratiques.
Ce sont les grandes entreprises du web amenées à traiter des volumes de données très importants qui ont été les premières confrontées aux limitations intrinsèques des SGBD relationnels traditionnels. Ces systèmes fondés sur une application stricte des propriétés ACID et généralement conçus pour fonctionner sur des ordinateurs uniques, ont rapidement posé des problèmes d'extensibilité.
Afin de répondre à ces limites, ces entreprises ont commencé à développer leurs propres systèmes de gestion de bases de données pouvant fonctionner sur des architectures matérielles distribuées et permettant de traiter des volumes de données importants. Les systèmes propriétaires qui en ont résulté, Google (BigTable), Amazon (Dynamo (en)), LinkedIn (Voldemort), Facebook (Cassandra puis HBase), SourceForge.net (MongoDB), Ubuntu One (CouchDB), Baidu (Hypertable) ont été les précurseurs du modèle NoSQL.
Les performances restent bonnes avec la montée en charge en multipliant simplement le nombre de serveurs, solution raisonnable avec la baisse des coûts, en particulier si les revenus croissent en même temps que l'activité5. Les systèmes géants sont les premiers concernés : énormes quantités de données6, structuration relationnelle faible (ou de moindre importance que la capacité d'accès très rapide, quitte à multiplier les serveurs).
Un modèle typique en NoSQL est le système clé-valeur, avec une base de données pouvant se résumer topologiquement à un simple tableau associatif unidimensionnel avec des millions — voire des milliards — d'entrées. Parmi les applications typiques, on retrouve des analyses temps-réel, statistiques, du stockage de logs (journaux), etc.